全站式搜索引擎设计的关键研究议题及精准度提升策略
日期 : 2026-04-26 01:24:58
全站式搜索引擎设计的关键研究议题及精准度提升策略
全站式搜索引擎作为覆盖多源异构数据、支持全场景检索需求的核心信息检索工具,其设计过程需突破传统搜索引擎的局限,兼顾数据覆盖的全面性、检索响应的高效性与结果匹配的精准性。本文从设计全流程出发,深入剖析核心研究议题,并结合当前技术实践,提出针对性的精准度提升策略,为全站式搜索引擎的研发与优化提供参考。
一、全站式搜索引擎网站设计的关键研究议题
全站式搜索引擎的设计核心是“全量覆盖、精准匹配、高效响应”,其关键研究议题贯穿数据采集、索引构建、检索排序、用户意图理解四大核心环节,各议题相互关联、相互制约,共同决定搜索引擎的整体性能。
(一)多源异构数据采集与质量管控
全站式搜索引擎的核心优势在于“全站覆盖”,需采集网站内所有类型的数据,包括静态网页、动态渲染内容、数据库存储信息、多媒体资源(图片、视频、文档)等异构数据,这是设计过程中的首要研究议题。
核心研究重点包括三个方面:一是多源数据的高效抓取策略,如何针对不同类型数据(如JS动态加载页面、PDF文档、图片)设计差异化抓取方案,兼顾抓取效率与资源消耗,例如采用Python、Java、C++多语言爬虫协同的方式,利用Python的敏捷性处理复杂页面解析,Java的高并发性完成大规模URL下载,C++突破性能瓶颈处理计算密集型任务;二是数据去重与增量更新机制,全站数据量级庞大,重复数据会严重影响检索精准度与存储效率,需设计高效的去重算法(如布隆过滤器、SimHash),同时实现增量抓取,确保数据时效性,避免无效重复抓取;三是数据质量过滤,剔除低价值、违规、无效数据(如垃圾页面、恶意跳转、内容重复的冗余信息),建立数据质量评估体系,为后续精准检索奠定基础,例如通过MySQL存储URL任务状态,MongoDB存储原始页面数据,实现数据的分级管理与质量筛选。
(二)分布式索引构建与优化
索引是搜索引擎实现高效检索的核心,全站式搜索引擎的数据量级远超传统搜索引擎,单节点索引无法满足存储与检索需求,因此分布式索引的构建与优化成为关键研究议题。
核心研究重点包括:一是索引结构的选型与设计,需结合全站数据特点,选择适配多类型数据的索引结构,主流方案为倒排索引与正排索引结合,倒排索引用于快速匹配关键词与文档,正排索引用于存储文档完整信息,同时引入ElasticSearch等成熟组件构建索引集群,提升索引的可扩展性与检索效率;二是索引分片与负载均衡,将海量索引数据分片存储于分布式节点,设计合理的分片策略(如按数据类型、时间维度分片),避免单节点负载过高,同时实现分片动态迁移与故障恢复,确保索引服务的高可用性,通过Kafka消息队列解耦索引构建与数据采集流程,提升系统稳定性;三是索引压缩与更新优化,针对全站数据的动态性,设计增量索引更新机制,避免全量索引重建带来的资源消耗,同时采用高效的索引压缩算法,减少存储占用,平衡检索效率与存储成本。
(三)检索排序算法的设计与优化
检索排序是决定搜索引擎精准度的核心环节,全站式搜索引擎需面对“多类型数据、多检索意图”的场景,如何设计兼顾相关性、权威性、用户偏好的排序算法,是核心研究议题之一。
核心研究重点包括:一是相关性排序模型的构建,突破传统关键词匹配的局限,融合语义理解、上下文分析,引入BM25、TF-IDF等经典算法,同时结合BERT等预训练语言模型,实现关键词与文档内容的深度语义匹配,解决同义词、多义词、歧义句带来的匹配偏差问题,例如通过向量空间模型计算查询与文档的余弦相似度,提升匹配精准度;二是多维度排序特征的融合,除了内容相关性,还需融入文档权威性(如页面权重、作者可信度)、用户行为特征(如点击量、停留时间、收藏率)、数据时效性等多维度特征,建立多特征融合的排序模型,实现“精准匹配+个性化推荐”的双重目标,同时通过Redis缓存热点检索结果,提升排序响应速度;三是排序算法的可解释性与公平性,避免算法黑盒导致的排序偏差,确保不同类型、不同来源的有效数据都能被合理排序,同时减少算法偏见对检索结果的影响,提升用户信任度。
(四)用户检索意图的识别与解析
全站式搜索引擎的用户检索意图具有多样性、模糊性特点,用户输入的关键词可能包含多义性(如“苹果”可指水果、手机品牌),也可能存在需求模糊(如“便宜的机械键盘”未明确价格范围),因此用户意图的精准识别与解析是提升检索精准度的关键前提,也是设计过程中的核心研究议题。
核心研究重点包括:一是意图分类与识别,将用户检索意图分为信息型(如“Python怎么学”)、导航型(如“微信官网”)、事务型(如“买200元以下的书包”)三类,通过规则模板与机器学习模型(如BERT)训练意图分类器,实现意图的精准识别,例如通过关键词中的“买”“价格”等词汇快速判断事务型意图;二是模糊意图的解析与扩展,针对用户输入的模糊关键词,通过同义词扩展、上下文补全、用户历史行为分析等方式,还原用户真实需求,例如将“跑部鞋”纠正为“跑步鞋”,将“便宜的机械键盘”扩展为“200元以下机械键盘”,同时提取搜索词中的核心实体(如品牌、年龄、属性),优化检索范围;三是多模态检索意图的适配,针对图片、视频等非文本检索需求,实现文本关键词与多模态数据的跨模态匹配,识别用户的多模态检索意图,打破单一文本检索的局限,构建多模态统一检索体系。
(五)隐私保护与系统可扩展性
随着数据安全法规的完善与用户隐私意识的提升,全站式搜索引擎在设计过程中需兼顾数据利用与隐私保护,同时考虑系统的可扩展性,以应对数据量增长与功能迭代需求,这也是当前的重要研究议题。
核心研究重点包括:一是用户隐私保护机制,在数据采集、存储、检索过程中,对用户敏感信息(如检索记录、个人偏好)进行加密处理,采用匿名化技术避免用户身份泄露,同时设计隐私合规的用户行为分析方案,平衡个性化推荐与隐私保护,避免过度采集用户隐私数据;二是系统可扩展性设计,采用微服务化架构,将数据采集、索引构建、检索排序、意图识别等模块解耦,实现各模块的独立伸缩与迭代,适配数据量增长与功能扩展需求,例如通过PHP驱动前后端,结合ElasticSearch、Redis、Kafka等组件构建松耦合的分布式架构,提升系统可维护性与可扩展性;三是多语言与跨语言检索适配,针对多语言数据场景,设计跨语言语义匹配算法,解决资源稀缺语言的检索效果问题,提升全站式搜索引擎的通用性与覆盖范围。
二、全站式搜索引擎精准度提升策略
基于上述关键研究议题,结合当前搜索引擎技术的发展趋势,从数据质量、索引优化、算法升级、意图理解四个维度,提出全站式搜索引擎精准度的提升策略,实现“全量覆盖、精准匹配、个性适配”的目标。
(一)强化数据质量管控,夯实精准检索基础
数据质量是精准检索的前提,需从采集、过滤、更新三个环节入手,提升数据质量:一是优化多源数据采集策略,针对不同类型数据设计差异化抓取规则,采用多语言爬虫协同作战,集成Splash、Playwright等工具处理JavaScript动态渲染页面,引入IP代理池、用户代理轮换等机制应对反爬策略,确保数据采集的全面性与完整性,同时通过MySQL管理抓取任务,MongoDB存储原始页面数据,实现数据的规范化管理;二是建立多维度数据过滤机制,结合规则过滤(剔除违规、垃圾内容)、算法去重(SimHash、布隆过滤器)、人工审核(重点数据校验),剔除低价值、冗余、无效数据,保留高质量、高相关性数据,同时建立数据质量评估指标(如内容完整性、准确性、时效性),定期对数据进行校验与更新,确保数据质量持续达标;三是优化增量更新机制,基于数据变化频率,设计差异化的增量抓取周期,对高频更新数据(如新闻、动态内容)采用实时抓取,对低频更新数据(如静态文档)采用定期抓取,同时实现索引的实时更新,确保检索结果的时效性,避免因数据滞后导致的精准度下降,通过Kafka消息队列实现数据采集与索引构建的异步协同,提升更新效率与系统稳定性。
(二)优化索引结构,提升检索匹配效率
索引结构的合理性直接影响检索效率与精准度,需从结构设计、分片优化、压缩更新三个方面进行优化:一是优化索引结构设计,采用“倒排索引+正排索引+向量索引”的混合索引结构,倒排索引用于快速关键词匹配,正排索引用于存储文档完整信息,向量索引用于语义匹配与多模态检索,适配多类型数据的检索需求,同时基于ElasticSearch构建索引集群,提升索引的检索效率与可扩展性,结合Redis缓存热点索引与检索结果,进一步缩短响应时间,实现毫秒级检索响应目标,契合全站式搜索引擎的高效性需求;二是优化索引分片与负载均衡,根据数据类型、时间维度、访问频率进行合理分片,将高频访问数据分片存储于高性能节点,低频访问数据分片存储于普通节点,同时实现分片动态迁移与故障恢复,避免单节点负载过高导致的检索延迟,确保索引服务的高可用性,通过微服务化架构实现索引模块的独立伸缩,适配数据量增长需求,提升系统的扩展性与稳定性,为精准检索提供高效支撑;三是优化索引压缩与更新策略,采用词典压缩、差值编码等高效压缩算法,减少索引存储占用,平衡检索效率与存储成本,同时设计增量索引更新机制,仅更新变化的数据,避免全量索引重建带来的资源消耗,确保索引与数据的同步性,提升检索结果的精准度与时效性,避免因索引滞后导致的匹配偏差,保障用户检索体验
 相关文章
相关文章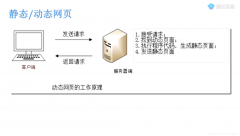

 精彩导读
精彩导读

 热门资讯
热门资讯